道具としてのExcel活用
今更聞けない、「csvデータとは何か」を他との比較で考えて見る
CSVファイルと、他の類似ファイルとの違い
目的は二次加工。そのために、一定の前提(ルール)が必要。
本来は汎用的な互換データ
かつてはA社のソフトウェアで作成したデータが、B社、C社で使えないのは当たり前でした。
しかし、他社のソフトウェアに乗り換えたら、既存のデータを全て捨てなくてはならないというのは余りに利用者を考慮していない、ということで、ファイルの”互換”が重視されるようになっていきます。
CSV形式ファイルも同様の流れで、上下左右に区切る必要がある場合(表計算やデータベース)に汎用的に使える様、「カンマで区切られたら次のフィールド」と言った単純なルールで表現されおり、ソフトウェア相互のデータ交換がしやすいようになっています。
多くの場合、csvファイルをWクリックすると、Excelが起動しますが、これはExcelをインストール時にCSVファイルのデフォルトアプリケーションをExcelに設定しているからです。
基本はテキストファイルなので、メモ帳などのエディタでもワープロでも・・・文字を扱えるソフトウェアならたいてい開くことができます。
Excelで、F12キーを押すと、他にも保存できる形式の一覧が表示されますが、csv形式以外にもタブ区切りなSYLKなど様々な形式で保存できることがわかります。
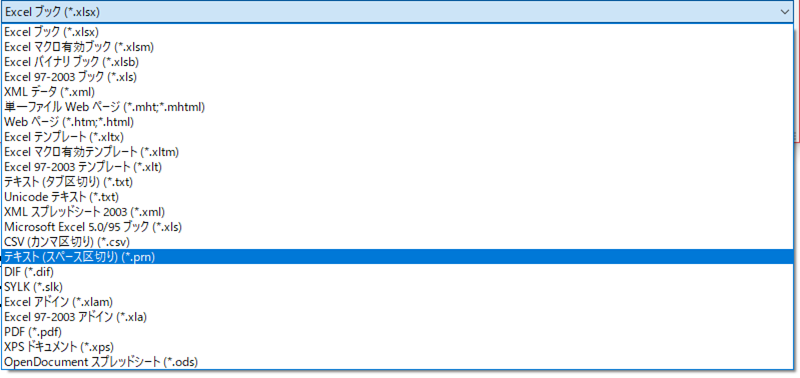
実は規格がある(RFC4180)
Excelシートであれば、どのような内容であっても「csv形式保存」ができるので、カンマで区切られていれば良いだろう、と考えがちですが、じつは規格があります。
技術資料書を見ると難しそうですが、利用者目線であれば、「互換性を保つためにどうするか」といった内容になります。
Excelの「名前を付けて保存」で作る、CSVファイル
上記(ファイル形式)は、「名前を付けて保存」機能の際に使えますが、単にファイル名を変更するだけでなく、ファイル形式の変更もできるわけです。
この機能を使って、CSV形式ファイルを選択すれば、セル単位でカンマに囲まれたテキストファイルに変換されます。
では、こうしてCSV形式で保存したデータは、何にどのように使うのでしょうか?
CSVファイルは、文字情報のみ
式や関数・ピボットテーブルは、全て文の情報が削除される
CSV形式ファイルは、メモ帳でも開ける”テキスト形式ファイル”、すなわち文字だけのファイルです。文字以外、色の情報や罫線・式としての情報は一切含まれません。これは、元々データとして交換できることを意図して作られた規格だからです。
従って、表として保存すれば、相対位置が変わらないことから、罫線がない状態で数字のみ同様に再現されます(式を排除したい場合に、よく使います)。
一方、式や関数は値化されていることから、再計算ができません。式を式として再現できるようにしたければ、SYLK形式を使います(これもText形式ファイルの一種)。しかし、表計算ソフト以外のソフトウェア(例:データベース)で読み込んだ際には、式として認識されないので、そのままの文字列として扱われます。
つまり、計算が終わった「結果」として変更できない状態にし、以後の処理で汎用的な加工を想定しておくのがCSVファイルの役割と言えそうです。
「汎用的」の意味
csvファイルは表計算用に作られたというわけではなく、汎用的に利用可能、という説明が多いようです。これは、ソフトウェアに限らず、機器類から出力されるデータとしても活用されていることを含んでいます。
たとえば、Webサーバのアクセス解析用に用いるデータは多くがcsvファイルとして記録されていますし、買い物の時に見かけるPOSレジでも、売上データがcsvデータとして取り出せます。工場の生産機器でも動作記録がcsvデータとして残りますし、家庭の電力消費状況も回路別に残せるものがあります。身近なところでは、アメダスの気象データもまた、csv形式で出力されます。
つまり、ソフト/ハードウェアの垣根を越えて互換性がとれるようになっています。
表形式でないCSVファイル
以前相談を受けたことがありますが、Excelで作った請求書ファイルを、全てCSV形式に変更したと(ファイルサイズが圧倒的に小さくなります)。これはCSV形式ファイルだから、そのままExcelから読み込んで、元の請求書を再現したい、ということです。
しかし、「請求書」の見出し文字が入っていたり、日付や相手先名が思わぬところに入っていたりいなかったり、更に改ページした場合はご丁寧にフッタ/ヘッダまでページ単位で再現されていました。
こうなると、元のレイアウト情報が失われているので、戻すことは事実上不可能です。
このように、csv形式ファイルがデータであって、その他の情報を持っていないことを認識していないと、ファイルを軽くするために全てcsv形式に変換して取り返しのつかない状況になってしまうことになりかねません(実際にそのような例でのご相談でした)。
他の類似ファイル形式(タブ区切り、SYLK、テキスト区切り)
他にも似たような「テキスト形式データ」で保存ができますが、それぞれ内容が異なります。
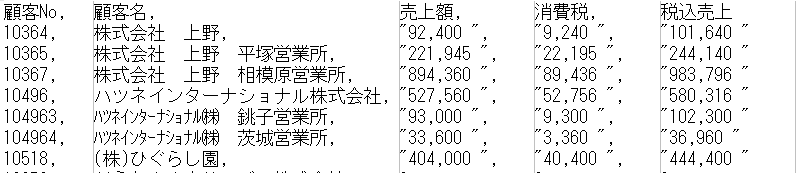
まず、次のようなExcelファイル(売上一覧+税額計算)を用意します。
csvファイルは、","で区切りたくない場合に、ダブルコーテーションでくくる
これをまず、csv形式ファイルとして保存したものがこちらです(前掲)。
表示しているエディタの機能上、項目(フィールド)の境目に縦線が入って整形されて見えますが、基本的にフィールドごとにカンマ","で区切られていることがわかります。
ところで、売上額以降は、ダブルコーテーション""でくくられているのがわかるでしょうか? これは、金額表示をした際に3桁ごとにカンマを入れることが多いのですが、そこで区切られては困るので、ダブルコーテーションでくくられた範囲を1つのフィールドとして扱えるようにしているためです。
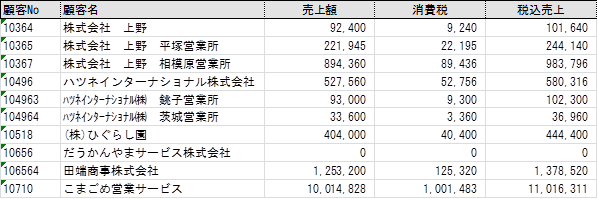
tab区切りは、データ内にカンマがあっても干渉しない
csvファイル内に、カンマがあると誤動作する可能性があることから、タブ(tab)で区切る方式が生まれます。俗にtsv(Tab Separated Values)とも呼ばれ、比較的よく利用されます。サポートしていない環境もあるので、互換性は若干低くなります。
基本的にデータとしての利用目的なので、そのまま印刷すると見づらいのはcsv形式と同様です。

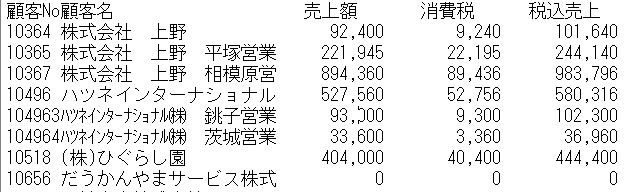
テキスト区切りは、そのままで印刷に耐える
テキスト形式で保存すると、そのまま印刷しても縦の列がすっきり合うため、文字情報しか送れない環境では重宝しました。ただし、データ量がcsvやtsvに比べて増えるのと、データとしての二次加工性はあまり期待できません。固定長データといいますが、「平塚営業所」の「所」が切れてしまっていますが、見た目に合わせて項目ごとの幅を無理矢理合わせてしまうためです。
SYLK形式は、式を再現できる他、色情報なども保持可能
SYLK形式ファイルでは、式の情報(初期の表計算でサポートしていた程度の、初歩的な式)や罫線や色などの情報(必要最小限)を保持しています。データとして二次加工性を期待するなら、表計算ソフトで扱うことが前提となります。

二次加工想定でなければ、意味が無い
データとレイアウト情報は意味が異なる
htmlファイルに学ぶ、レイアウト表現
今見ているブラウザに表示されている文字列・画像などは、いずれも「html形式ファイル」という様式で記述されています。
htmlは、Webブラウザにレイアウトを定義するための様式です。

例えば"<br>"と記述すれば、改行を意味し、"<u>~</u>”と記述すれば、囲われた範囲に下線を引きます。
他にも表形式で表したり画像を挿入したりハイパーリンクを設定したり・・・といったことができます。
同様に、何かレイアウト(位置情報)を必要とするならば、同様の表現についての情報が必要です。
しかし、CSV形式ファイルにはそのような情報は含まれていません。
CSVファイルは互換してこその価値
他のソフトウェアとの互換=二次加工性
先の例で、A社のソフトウェアのデータが、B社、C社のソフトウェアで読めない、という例を引合いに出しましたが、一般的に互換性が求められるのは、「記入時はExcelだが、集計したらデータベースに集計し、最終的にはパワポ形式で印刷する」といった、異なる役割のソフトウェア間連携でしょう。要するに、各業務工程において、前の工程の下項結果(データ)を二次加工、三次加工・・・して使える必要があるのです。

こうした互換(二次加工性)を保つ場合の暗黙の了解としては、
- 全ての行が同様の構造をしている
- ヘッダは上部に1回だけ出現し、他はそれを共有する
- カンマとカンマの間が1つの項目(フィールド)となるので、情報にカンマを含められない
- やむを得ずカンマを入れる場合(数値の区切り文字など)は、全体を””でくくる
といったことが挙げられます。
互換させないCSVファイル
世の中には、他のソフトウェア(処理系)に勝手な処理をさせないためか、独自様式のCSV(と言えなくもないファイル)が存在します。
その特徴は、
- 行によって項目数が異なる(項目を揃えるのが大変)
- ヘッダが途中で何度も不規則に出現する(処理対象外にするのが大変)
- 列によって””で囲ってあるところと層で無いところがある(揃えないと、機械的な処理ができない)
- 途中で改行コードが入る(その結果、行によって構造が変わる)
といった状態で、所謂IT企業が作成するデータにこの傾向が見られます。

こうしたデータは、そのまま二次加工ができないので、処理前に特別な加工を行った上で、初めて二次加工できるようにできます。
CSVファイルだからといって、Excelで処理できるとは限らない
例えば国内大手のショッピングモールサイトの売上データは、途中から""で囲われていたり、改行コードが入っていたり、途中で文字化けしていたり・・・と、機械的な処理が非常に難しいデータです。
他にも電力消費データがプランによって項目が異なっていたり、データだけ見ても処理できないような”CSVデータ”が多数存在します。
業務を自動化しようとする発想があるならば、予めこうした「形だけCSVファイル」ができないよう、ご留意下さい。Excelで開けば自動的に補正してくれる部分もありますが、その分欠落する情報も多いので、機械的な処理ができないケースが多いのです。
まずは、業務の標準化から
各工程の業務を標準化する=互換性をとる、ことになりますから、Excelで作るデータ形式をどうこうする以前に、相互のデータを標準化(ルール決め)しておく必要があります。
標準化が担保されていれば、二次加工が前提となるので、「手で入れ直す」作業は原理的に0にできます。